Cloud Models
When a task exceeds what local models can handle — complex reasoning, frontier-level code generation, or large-context analysis — LA Router seamlessly escalates to cloud model APIs. This happens transparently, with the same /v1/chat/completions interface.
How Cloud Routing Works
LA Router's classifier assigns each request a complexity tier. Tasks classified as Complex or Frontier are automatically routed to cloud APIs:
Your App → LA Router → Classifier
│
┌───────────┼───────────┐
▼ ▼
Complex Frontier
(Cloud API) (Cloud API)
│ │
▼ ▼
Gemini Pro Claude Opus
GPT-4o Gemini Ultra
Private Cloud Models
For organizations that require data sovereignty but need cloud-scale compute, LA Router supports private cloud deployments:
Self-Hosted LLM Servers
Route to models running on your own cloud infrastructure — private GPU clusters, VPCs, or on-premises data centers:
# Configure a private cloud endpoint in .env
PRIVATE_CLOUD_URL=https://llm.internal.yourcompany.com/v1
PRIVATE_CLOUD_API_KEY=your-internal-key
LA Router treats private cloud endpoints identically to public cloud APIs, with the same routing, token tracking, and billing features — but your data never leaves your infrastructure.
Key Use Cases for Private Cloud
| Use Case | Description |
|---|---|
| Regulated industries | Healthcare, finance, and legal where data cannot leave corporate networks |
| Large-scale inference | Tasks requiring GPU clusters beyond what a single workstation provides |
| Fine-tuned cloud models | Organization-specific models deployed on private infrastructure |
| Geographic compliance | Data residency requirements (GDPR, HIPAA, SOC 2) |
Public Cloud Models
For maximum capability on non-sensitive tasks, LA Router integrates with the leading public cloud LLM providers:
Supported Providers
| Provider | Models | Best For |
|---|---|---|
| Google Gemini | Gemini Flash, Gemini Pro, Gemini Ultra | Fast general-purpose tasks, multimodal |
| Anthropic | Claude Sonnet, Claude Opus | Complex reasoning, long-context analysis |
| OpenAI | GPT-4o, GPT-4o-mini, o1 | Code generation, structured output |
Configuration
Each provider is configured via API keys in your .env file:
# Public cloud API keys
GOOGLE_API_KEY=AIza...
ANTHROPIC_API_KEY=sk-ant-...
OPENAI_API_KEY=sk-...
LA Router will automatically select the best provider based on the task classification and your configured routing preferences.
Routing Decision: Local vs Cloud
LA Router makes the local-vs-cloud decision based on several factors:
Cost Optimization
One of LA Router's core benefits is automatic cost optimization. By routing simple tasks to free local models, you can dramatically reduce your API spend:
| Tier | Model | Cost per 1M Tokens |
|---|---|---|
| Heartbeat | Local 2B | $0.00 |
| Simple | Local 4B | $0.00 |
| Moderate | Local 26B | $0.00 |
| Complex | Gemini Pro | ~$1.25 |
| Frontier | Claude Opus | ~$15.00 |
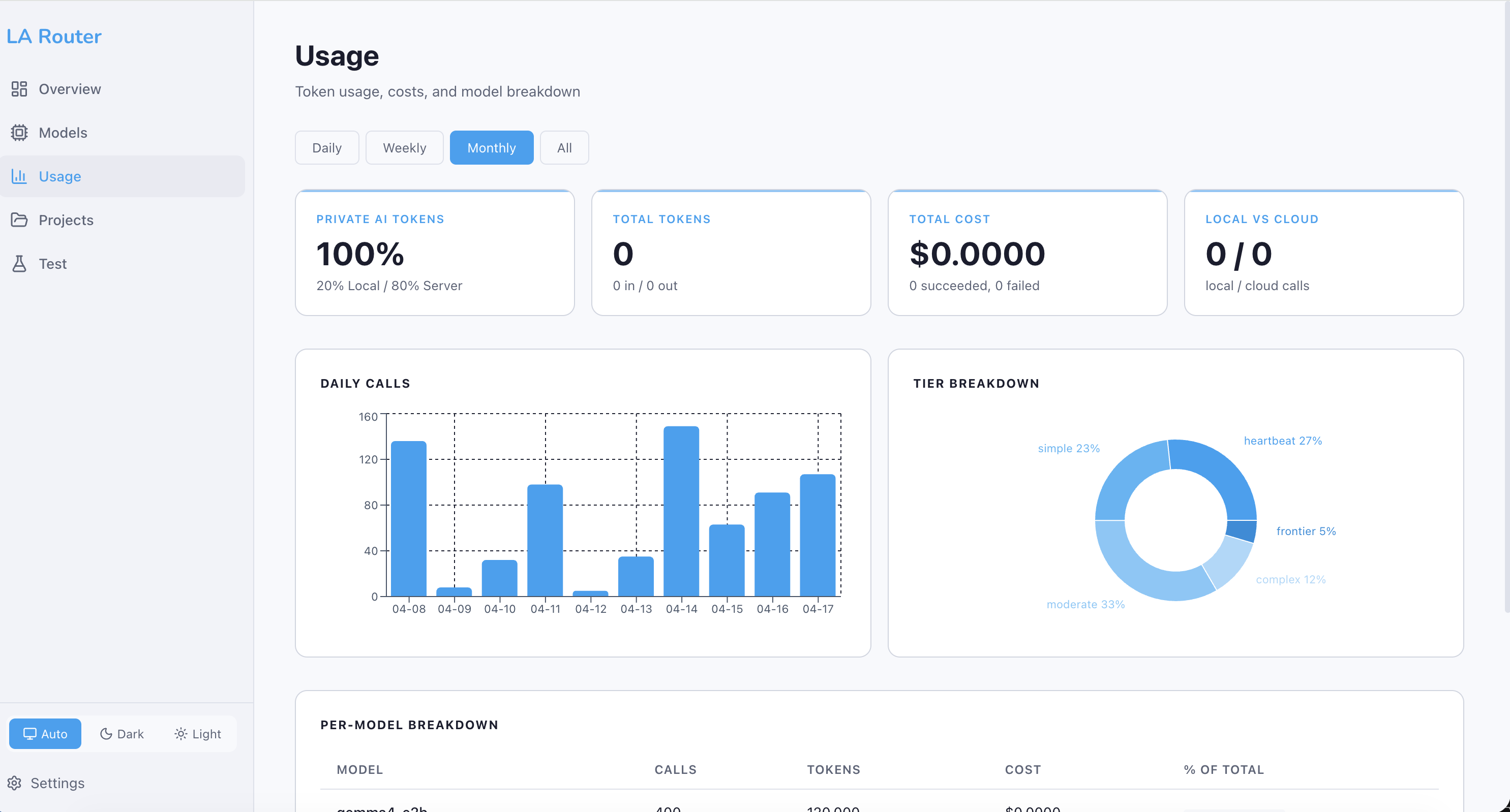
Organizations typically see 60–80% cost reduction by routing Heartbeat, Simple, and Moderate tasks to local models — which represent the majority of LLM calls in most applications.
Token Tracking
Regardless of whether a request goes to a local or cloud model, LA Router tracks all token usage with per-project, per-model granularity:
- Input tokens and output tokens counted separately
- Cost calculated using model-specific pricing
- Per-project budgets with alerting and hard caps
- Usage dashboard with charts and breakdowns
Privacy Model Summary
| Deployment | Data Leaves Network? | Cost | Capability |
|---|---|---|---|
| Local (Heartbeat/Simple) | ❌ No | Free | Basic tasks |
| Local (Moderate) | ❌ No | Free | Most business tasks |
| Private Cloud | ❌ No (your infra) | Compute cost | Full capability |
| Public Cloud | ⚠️ Yes (provider) | API pricing | Maximum capability |
LA Router gives you full control over which tasks can be sent to external providers and which must stay local — ensuring your data privacy requirements are always met.